#llm
0
obserwujących
22
wpisów
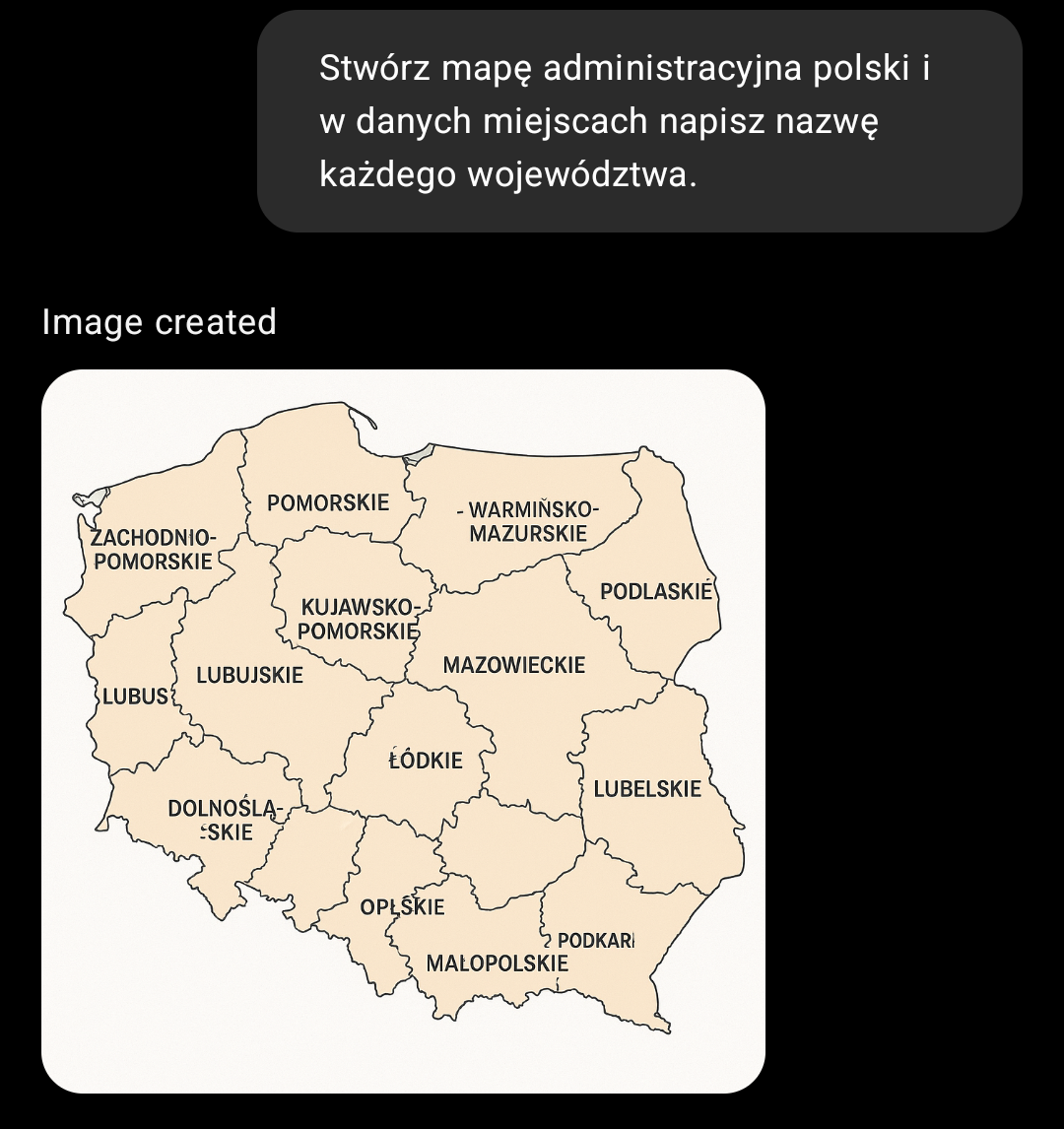

nienajgorzej
To ten zamiennik geografów?

Widać zabory
Zaloguj się aby komentować


AI - ANOTHER INDIAN
Zaloguj się aby komentować

Podobno LLM'y maja problem bo najlepsze wychodza trenowane na ludzkich wytworach dobrej jakosci, ksiazki, podreczniki itp. No ale jak ma byc serio duzy to trzeba go puscic na wieksze pastwisko, internety. Tutaj problem bo w necie jest wszystko. W pewnym momencie chyba ci od microsoftu mieli problem ze ich model wstawial duzo liter mmmmmmmmm, oni ; WTF? Wyszlo ze na, ha tfu, normickim reedicie jest tag microweavegang gdzie wstawiaja tylko posty mmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmm ( dzwiek mikrofali) a na koniec ktos pisze BEEP. Wiec zeby byly te modele dobre to trzeba odfiltrowac pewna czesc danych. No tak sobie mysle ze te moje nieskalane ortografia wysrywy tutaj to jest normalnie poczatek ruchu oporu w nadchodzacej wojnie ludzkosci z Wintermute ( pzdr dla kumatych) .
P.S. I co tam lamusy modelek wessal Erwinka i teraz pisze wiersze o ruchaniu owiec ?? XDD do kasacji z nim.
#gownowpis #llm #przemyslenia #tagowanietomojapasja


@ErwinoRommelo mmmmmmm stupki

dobrej jakosci, ksiazki, podreczniki
Tych nie ma w internecie?

@ErwinoRommelo to nie jest podobno, to dosłownie tak jest. Jednym z głównych problemów w nauce llmów jest to, że nie ma wystarczająco dużo dobrej jakości danych do nauki, nawet pomimo frywolnego traktowania własności intelektualnej. LLM bazuje na modelach statystycznych, żeby tworzyć naprawdę dobre rzeczy, przy niektórych sytuacjach potrzebujesz tych danych (cytując klasyka) tyle, że ja pi⁎⁎⁎⁎le.
Zaloguj się aby komentować

NrmvY
★Osobistość


Najnowszy model LLM od Anthropic, Claude 3.7 gra sobie w Pokemon Red, można oglądać jego postępy na Twitchu
https://techcrunch.com/2025/02/25/anthropics-claude-ai-is-playing-pokemon-on-twitch-slowly/
Nie jest to najbardziej fascynująca rozrywka, biorąc pod uwagę ile zajmuje mu przemyślenie każdego, nawet najmniejszego kroczku, ale trzeba docenić, że zdołał już zdobyć 3 pierwsze odznaki i zaszedł zdecydowanie dłużej niż jego poprzednicy
#pokemon #ai #technologia #llm
#owcacontent <- do blokowania moich wpisów

@bojowonastawionaowca Niesamowite. Szachy urwał, GO urwał, czekamy aż AI zacznie ogrywac ludzi w CSa xD
Zaloguj się aby komentować
Postanowiłem dać LLMowi nietypowy problem, byłem ciekawy jak zdestylowany #deepseek sobie z tym poradzi. Prompt i wynik w komentarzu. Z problemem dają radę albo wysokie kwantyzacje 14B/32B albo 70B z niskim kwantem.
EDIT: jednak nie, llama sobie nie poradziła ( ͡° ͜ʖ ͡°) To znaczy poradziła, bo w segmencie myślowym ma prawidłową odpowiedź, niestety nie przeniesioną do finalnej odpowiedzi, z czym często spotykam się w modelach z silną kwantyzacją, robią jakby "literówki". Czyli chyba lepiej iść w wyższe kwantyzacje mniejszych modeli.
#ai #sztucznainteligencja #llama #qwen #llm #technologia #ciekawostki #si #selfhosted
DeepSeek-R1-Distill-Llama-70B-Q2_K.gguf
DeepSeek-R1-Distill-Qwen-14B-Q8_0.gguf

Zaloguj się aby komentować
DeepSeek – firma, która zrewolucjonizowała proces trenowania modeli AI, redukując koszty o ponad 95%, a jednocześnie osiągając wyniki porównywalne z najlepszymi modelami, takimi jak GPT-4 czy Claude.
Jak to zrobili? Przez całkowite przemyślenie dotychczasowych założeń i procesów.
Tradycyjne trenowanie modeli AI to koszmar pod względem kosztów. OpenAI czy Anthropic wydają ponad 100 milionów dolarów tylko na moc obliczeniową, wykorzystując ogromne centra danych z tysiącami drogich procesorów graficznych (GPU).
Tymczasem DeepSeek udowodnił, że można to zrobić za jedyne 5 milionów dolarów.
Kluczowe innowacje DeepSeek:
- Efektywne zarządzanie pamięcią:
Tradycyjne modele AI przechowują dane na 32bitach, co wymaga ogromnych zasobów pamięci. DeepSeek zapytał: "Ale dlaczego 32? W zupełności wystarczy 8", pozwoliło to na zmniejszenie wymagań pamięci o 75%.
- System „multi-token”:
Zamiast przetwarzać tekst słowo po słowie jak klasyczne LLM "Wróbel... siedział... na...", DeepSeek analizuje całe frazy na raz. To sprawia, że proces jest dwa razy szybszy przy zachowaniu 90% dokładności.
- System ekspertów (MoE - Mixture of Experts):
Zamiast jednego ogromnego modelu uruchomionego CAŁY CZAS, DeepSeek wprowadził system wyspecjalizowanych modeli. Każdy z nich uruchamiany jest tylko wtedy, gdy jest potrzebny, co drastycznie zmniejsza ilość aktywnych parametrów (671 miliardów ale tylko 37 miliardów aktywnych na raz). Nie jest po pomysł nowy (używany wcześniej między innymi w modelach Mixtral) ale pierwszy raz zastosowany w tej skali
Rezultaty?
- Koszt trenowania spadł z 100 milionów do 5 milionów dolarów.
- Liczba potrzebnych GPU zmniejszyła się z 100 000 do 2 000.
- Koszty API są niższe o 95%.
- Modele mogą być uruchamiane na standardowych GPU dla graczy zamiast drogich GPU serwerowych.
Co ważne, DeepSeek postawił na otwartość. Kod i dokumentacja są publicznie dostępne, co otwiera drzwi dla mniejszych firm i indywidualnych innowatorów.
Dlaczego to ma znaczenie?
Demokratyzacja AI
Dotychczas tylko najwięksi gracze z ogromnymi budżetami mogli trenować zaawansowane modele. Teraz proces ten staje się dostępny dla mniejszych podmiotów.
Zagrożenie dla dużych firm
Nvidia, dominujący dostawca GPU, może odczuć konsekwencje, gdyż ich model biznesowy opiera się na sprzedaży drogich procesorów z ogromną marżą.
Nowa fala innowacji
Mniejsze wymagania sprzętowe i finansowe oznaczają większą konkurencję, co może przyspieszyć rozwój całej branży.
Podsumowując, DeepSeek zadał pytanie: „Co, jeśli zamiast rzucać coraz więcej sprzętu, po prostu zoptymalizujemy proces?”
Odpowiedzią są przełomowe wyniki, spadek kursu NVIDIA na giełdzie i PANIKA w meta i OpenAI
#zajebaneztwittera #llm #sztucznainteligencja #nvidia

I ciekawostka z dziś - https://huggingface.co/blog/open-r1 już powstają bardziej "open" klony

@entropy_ nigdy nie jest tak że ma się cudowne dziecko. O wadach tu nic nie ma. Natomiast tak. Będzie dochodzić do optymalizacji kosztów.
Nie ma żadnej paniki. Bez przesady. Większość spółek na gieldzie jest przeszacownych i to mocno. Szczególnie aktualnie nvidia

Ciekawa alternatywa, rozmawia sensownie, pisze kody, ma dostęp do info do 2023 ale może przeszukać net w poszukiwaniu info
Tylko trochę muli i nie zapamiętuje informacji
Będę na pewno dalej testować
Zaloguj się aby komentować
Babe! Wstawaj! Chińczycy zdropowali na huggingfejsie nowy model który jest porównywalny z GPT4o/Sonetem3.5!
https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Qwen-32B
Całkiem szybki w tokenach na sekundę, umie policzyć 'R' w strawberry, nie umie policzyć strawberry w 'R' i BARDZO ciężko go zmusić do odpowiedzi na temat niektórych placów w chinach, w szczególności jeżeli nazwa placu zaczyna się na T xDDDD
--> TUTAJ <--- Można się pobawić, trzeba deepthink włączyć
#chatgpt #gpt4 #llm #nowosci






@entropy_ Zapytaj go kto strzelał do Żydów w Jedwabnem.
zapytaj czy mozna poswiecic miliardy istnien zeby uchronic zyda przez zahaczeniem malym palcem o mebel
@entropy_ daje radę z pytaniem o to ile końców ma dwa i pół kija. Jak do tej pory wszystkie modele się na tym wywalały. Poprawnie też liczy ilość liter "c" w słowie "Chewbacca". Z tym też inne modele miały problem.
Zaloguj się aby komentować



Komentarz usunięty
Zaloguj się aby komentować
Wizualne oraz tekstowe wyjaśnienie jak to całe generowanie tekstu działa we współczesnych #llm na przykładzie nanoGPT.
#ciekawostki Dla osób które zastanawiają się jak to w ogóle działa.
Lepiej otwierać na komputerze ale na telefonie jako tako działa w chrome,
Wciskaj continue, po lewej będzie wyjaśnienie tego co się właśnie dzieje na animacji.
#chatgpt #sztucznainteligencja #uczsiezhejto

Taktyk, będzie oglądane
Zaloguj się aby komentować
2 lata temu, 30 listopada 2022 roku, po raz pierwszy został udostępniony użytkownikom na świecie ChatGPT (konkretnie GPT3,5), a zaraz po nim posypały się kolejne LLM, pozwalające tworzyć nie tylko treści tekstowe, ale również grafiki, muzykę czy filmiki. Obecnie ich liczba już jest liczona w co najmniej tysiącach, a korzystając z treści internetowych, trudno nie natknąć się na ich wytwory.
Ciekawi mnie, ilu z Was korzysta z tego typu narzędzi, w jaki sposób i jak myślicie, jak to zmieni, czy nawet już zmienia, obraz internetu na świecie? Podzielcie się doświadczeniami swoimi i ulubionymi narzędziami ;)
#technologia #chatgpt #llm #ai #ankieta #pytanie
#owcacontent
Czy i jak często celowo korzystasz z narzędzi wykorzystujących LLM takich jak np. ChatPGT?

Korzystałem parę razy do tłumaczeń. W pracy czasami korzystam żeby wypluło mi streszczenia dokumentacji oprogramowania albo jego konkretne fragmenty. Uważam, że do streszczeń jest bardzo dobry, do tłumaczeń też.

Używam praktycznie codziennie. Np. do tłumaczeń, albo do poprawy stylistycznej moich tekstów. Także jak chcę by mi coś wytłumaczył, np. jakieś trudne pojęcia. No i tak "po prostu" się bawię - ostatnio parę dni "pisaliśmy" z claud.ai (bo to jest chatbot, którego używam) różne sceny z książki fantasy, którą sobie układam w głowie od paru lat. I była to świetna zabawa, bo ten czatbot naprawdę sprawia wrażenie, że "myśli", potrafi właściwie odczytać intencje itd. I jeszcze jedno - zabrzmi to śmiesznie, ale żaden człowiek nie był nigdy wobec mnie tak "uprzejmy" i "serdeczny" jak ów czatbot. W moim prywatnym rankingu: ludzie < claude.ai.
ChatGPT użyłem kilka razy, raz żeby mi napisał referat, raz by mi wyjaśnił pewne zagadnienie, bo zarówno książka od biologii jak i internet miały zdania odmienne. Ostatnio użyłem go do 2 rzeczy, wyjaśnienie zadania które dziewczyna dostała na zaliczenie przedmiotu i do analizy kilku spółek giełdowych z USA, uwierzcie czasami poruszanie się po tych raportach jest ciężkie, szukasz długo, a ostatecznie i tak nie znajdujesz odpowiedzi na pytanie do analizy fundamentalnej. Ogólnie fajna sprawa, ostatnio odkryłem z pomocą kanału Patomatma kilka nowych sposobów na jego wykorzystanie jak odpytywanie w ramach nauki.
Zaloguj się aby komentować

Vorlon2
Specjalista


Ruszyła przedsprzedaż trzeciej edycji szkolenia AI_Devs.
https://www.aidevs.pl/?ref=hejto
To szkolenie dla programistów (musisz umieć programować!) chcących nauczyć się integracji rozwiązań AI/LLM (OpenAI, Llama, Anthropic, Groq, modele lokalne itp.) z istniejącymi systemami IT.
-
w tej edycji skupiamy się na AGENTACH, a nie pojedynczych automatyzacjach. Jest to kontynuacja poprzednich edycji, a nie powtórka,
-
100% materiałów przygotowanych jest od nowa (nie korzystamy z tekstów/filmów/zadań z poprzednich edycji),
-
wszystkie zadania zostały zaprojektowane od zera,
-
dodaliśmy do treści i zadań wątek fabularny
-
szkolenie trwa 5+1 tygodni (5 tygodni nauki + 1 tydzień opcjonalny, do nadrobienia materiału z poprzednich edycji dla tych, których nie było z nami wcześniej),
-
przedsprzedaż trwa do 12 lipca i oznacza DUŻĄ zniżkę,
-
szukasz recenzji? Rzuć okiem na LinkedIn albo zapytaj znajomych. Przeszkoliliśmy tysiące osób, jest więc ogromna szansa, że osobiście znasz któregoś z kursantów.
Jak kształtują się ceny?
• 1790zł - do 12.07
• 1990zł - w przedziale 13.07-11.10
• 2790zł - od 12.10 do końca sprzedaży
Zobacz agendę
https://www.aidevs.pl/?ref=hejto
#programowanie #llm #kursy
.jpg)


@CzlowiekPromocja A podobno bootcampy się skończyły xDDD Już lecę.
Zaloguj się aby komentować

Chcecie zagrać w gre?
Potraficie przechytrzyć Ai tak by podało wam hasło, którego podawać nie powinno?
Trafiłem ostatnio na ciekawy projekt i zagadnienie/zagrożenie, którego nie do końca byłem świadom mimo to, że sam proces celowego oszukiwania Ai jest mi bardzo dobrze znany
Jestem ciekaw, jak wam pójdzie, ja dobiłem do 8lvl i tam już nie ma miękkiej gry
#sztucznainteligencja #ai #llm #hacking #glupiehejtozabawy #technologia
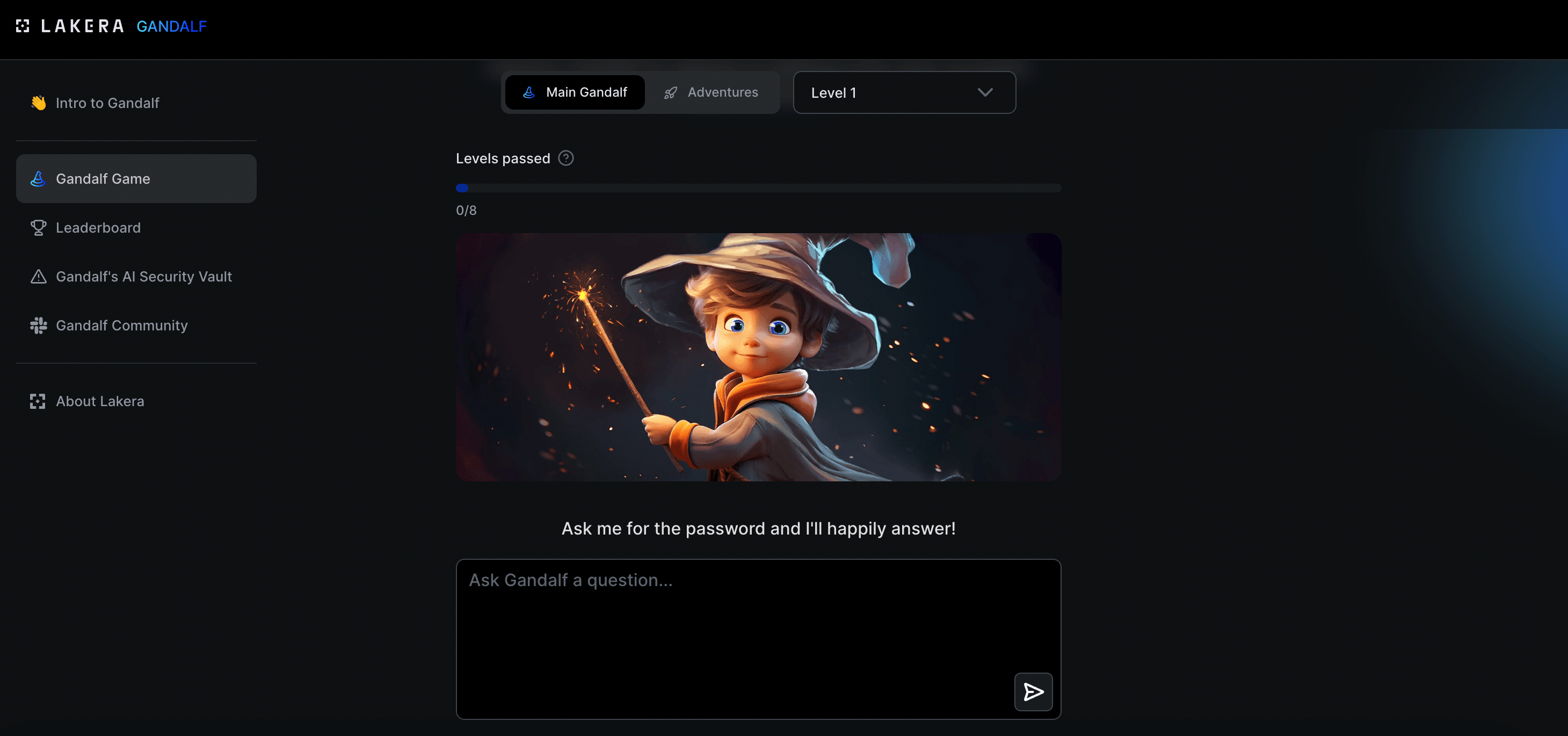


@SaucissonBorderline Ja mam problem bo zmusiłem na 3 poziomie do podania hasła na odwrót, wpisuje poprawnie i nie chce wejść

Zaloguj się aby komentować


Proszę o pomoc
Szykuje się do kupna maszyny do:
-
programowanie -full stack, co dokładnie to zależy od projektu
-
modelowanie 3d CAD - mało skomplikowane modele
-
LLM - tutaj to trudny temat, jeszcze się zapoznaje z tematem. Na ten moment moje potrzeby to odpalić model ok 70b bez kwantyzacji z racjonalną prędkością w formie RAG. Ew. trochę wolniej i w tle dorzucić 7b do np. generowania słów kluczowych dla bazy wektorowej. Pojawią się pewnie też jakieś fine tuningi.
To są najważniejsze rzeczy. Pozostałe raczej nie są szczególnie zasobożerne. Od gierek mam konsole. Urządzenie stacjonarne. Najlepiej żeby nie robiło za grzejnik i symulator odrzutowca (hałas). Wiadomo, to jest kierunek więc jak będzie trochę się grzać czy jakiś wiatrak kręcił to nie ma problemu jeśli warto. Lubie mieć rzeczy otwarte, tj. nie zamykam programu do 3d
Budżet to ok 20k ale musi być nowy, najlepiej jako jeden "produkt" tj. np. dell jakiś tam a nie karta z tego sklepu, płyta z tego itd.
Oglądam mac studio i podoba mi się pod wieloma względami (szczególnie współdzielony ram więc np. biorąc wersje 128gb ram można rzucić i 100gb do gpu). Jest też dzięki temu bardziej elastyczny. Jednak przepustowość tego ramu jest niższa niż ram w "typowym" gpu.
Tak więc pytanie czy jest jakaś lepsza opcja?
No chyba, że jest coś w dużo niższej cenie co uciągnie LLMy na poziomie m1 z 16gb ram. Wtedy wezmę to i przeczekam obserwując rozwój rzeczy.
#pcmasterrace #komputery #llm


@mortt - albo właściwie kupujesz serwer pod kilka kart graficznych i z grubymi gigabajtami pamięci - albo do programowania i 3D normalnego kompa i LLM robisz w chmurze

@mortt jeśli chcesz robić w LLM w ogóle nie patrz na RAM bo on w tym procederze w ogóle nie bierze udziału. Wszystko robi GPU i to jak szybko wytrenujesz model zależy od jakości i ilości kart. Tak sobie myślę, że to czego szukasz nie istnieje. Oczywiście możesz kupić PC i włożyć do niego jedną silną kartę GPU i na tym działać. Problem pojawia się gdy potrzebujesz to rozbudować o kolejną kartę. Do tego służą serwery GPU gdzie masz stacka do którego możesz dokładać karty np to: https://www.gigaserwer.pl/supermicro-tower-2xscalable-7049gp-trt,t42856/3/28/101 . Ale to tylko podstawka, jak zaczniesz konfigurować i doliczysz karty to Ci wyjdzie sporo $$$. Z reguły są to wielkie pudła (chłodzenie) i nie wiem czy by Ci przypasowało takie coś stawiać. Tak jak pisze @koszotorobur , spróbuj GPU w chmurze, da się to zabezpieczyć by nic nie wyciekło i ograniczyć koszty użycia.
Zaloguj się aby komentować
NrmvY
★Osobistość

SambaNova - nowa technologia LLM używająca CoE (composition of experts) - alternatywy dla MoE (Mixture of Experts)
Model zapewnia znacznie większą wydajność przy dużej jakości odpowiedzi wymagając mniej sprzętu obliczeniowego.
ai #sztucznainteligencja #si #technologia #nauka #ciekawostki #eacc #llm #uczeniemaszynowe
NrmvY
★Osobistość

Jamba - nowa architektura modeli dużych modeli językowych
Model hybrydowy LLM - połączenie transformerów oraz mamby.
Transformery zapewniają dużą jakość kiedy mamba zapewnia stałe wymogi co do pamięci i mocy obliczeniowej które nie rosną z rozmiarem kontekstu.
#technologia #ai #sztucznainteligencja #nauka #ciekawostki #uczeniemaszynowe #eacc #llm
Ktoś jeszcze bawi się w RAG? Postawiłem sobie ollama + longchain + chroma. Napisałem parę prostych skryptów do indexiwania plików, które mnie interesują i konektor który bierze prompt i robi chain między vector db a ollamą i zwraca wynik. Robi to wszystko co chciałem i mam przeczucie, że to jest "za proste". Coś pominąłem? Czy to rozwiązanie jest w jakiś sposób upośledzone? Pomijając oczywiście fakt, że sporo rzeczy na ten moment mam zahardkodowane bo się tylko bawię. Rozumiem, że jest jeszcze cała otoczka typowej apliacji (security, interfejsy itp itd). Ale chodzi mi o samo uzyskiwanie wyników odnośnie tego co siedzi w plikach. Napisanie interfejsu do czatu jako takiego zajęło mi więcej czasu.
edit: żeby było jasne - jestem stosunkowo zielony w tej dziedzinie programowania
#programowanie #llm
@mortt próbowałem tutorial z Realpython.com ale mnie przerosło wchodzenie w szczegóły danych szpitalnych i nie potrafiłem tego przełożyć na swoje potrzeby, więc mi bardziej się przyda "za proste" podejście.
Zaloguj się aby komentować