

#openai
4
obserwujących
111
wpisów

Marchew
★Autorytet
Nowy bot dla zastosowań domowych.
Tak wiem, po zmianie modelu pralki najprawdopodobniej nie będzie już potrafił jej obsłużyć.
Ale i tak robi wrażenie.
Figure 03
#ai #openai #figure
@Marchew robot humaidalny to porażka ekonomiczna, lepsiejrzy byłby coś a'la centaur, podwozie na 4 nogi i tułów z ramionami chwytnymi
Zaloguj się aby komentować


OpenAI pozwane przez rodziców nastolatka. Chłopiec miał popełnić samobójstwo pod wpływem ChatGPT
Matt i Maria Raine z Kalifornii pozwali do sądu firmę OpenAI w związku z samobójczą śmiercią swego 14-letniego syna Adama. Rodzice twierdzą, że ChatGPT zachęcał go do odebrania sobie życia.
To pierwszy przypadek, gdy przeciw OpenAI podjęto działania prawne w związku z zawinieniem śmierci.
Do pozwu...
Załóżmy że to co mówią w tym filmie na początku to prawda: Altman buduje samowystarczalny bunkier żeby przeżyć apokalipsę zgotowaną przez AGI/ASI.
Jeżeli Altman rzeczywiście twierdzi że AGI/ASI będzie przekraczać ludzkie możliwości pod każdym względem jaki jest sens budować bunkier do którego taki twór wejdzie jak do siebie, niczym "Papa do papakomnaty przez papawrota" #pdk
Amerykanie ponoć w ostatnim nalocie na Iran użyli bomb penetrujących do około 60m skał, takie AGI/ASI będzie mogło zaprojektować jeszcze lepszą amunicję, albo kto wie krety kopiące w żelbecie ( ͠° ͟ʖ ͡°) .
#sztucznainteligencja #openai #rozkminy
@m_h nie wiem czy mogę ufać gościowi, który żyje z nakręcania na sztuczną inteligencję, budowanie schronu może tu być zagraniem marketingowym
Zaloguj się aby komentować
Wpadłem ostatnio na koncepcję. Chodzi o stworzenie otwartej platformy, w której każdy mógłby stworzyć własnego agenta AI grającego w Settlers IV – bez modyfikowania gry, zewnętrznie, przez obraz i automatyczne sterowanie.
Wyobraźcie sobie:
AI, które uczy się grać jak człowiek – patrzy na ekran, klika, analizuje, podejmuje decyzje.
Ludzie tworzący własne mózgi osadników – czy to przez sieci neuronowe, heurystyki, własny styl gry albo... drzewo decyzyjne na 2000 linijek.
Otwarte repozytorium z możliwością testowania, uczenia, dzielenia się pomysłami.
To nie projekt na dziś, ale może na "kiedyś". Póki co – zostawiam piłkę na środku boiska.
Może kiedyś ją kopnę. A może ktoś kopnie pierwszy.
Settlers AI Lab. Dla pasji. Dla ludzi. Może kiedyś.
#ai #retro #gamedev #openai #projekt #settlers

... a może jednak nie twórzmy matrixa? 🤔

Jak co to pisz, czesto mi w csie mowia ze gram jak bot to chyba sie znam co nie

@DexterFromLab fajne! Ja bym uzyl by zastąpić kolegów do gry w mutli w starsze gry itp. Po studiach każdy rozpiszchl się i ciężko znaleźć kogolwiek do wspólnej gry a niektóre lepiej się gra w większym gronie.
Zaloguj się aby komentować

Amerykański sąd nakazuje OpenAI zachowanie USUNIĘTYCH wiadomości z ChataGPT
Jeśli ktoś by miał jeszcze wątpliwości czy bezrefleksyjne korzystanie z amerykańskich produktów i usług stanowi zagrożenie. Problem dotyczy użytkowników z całego świata, także płacących.
komputery #technologia #sztucznainteligencja #sztucznainteligencja #si #ai #chatgpt #openai #prawo

Ciekawostka na dziś:
#technologia #sztucznainteligencja #ciekawostki #ai #deeplearning #chatgpt #openai #deepseek #grok
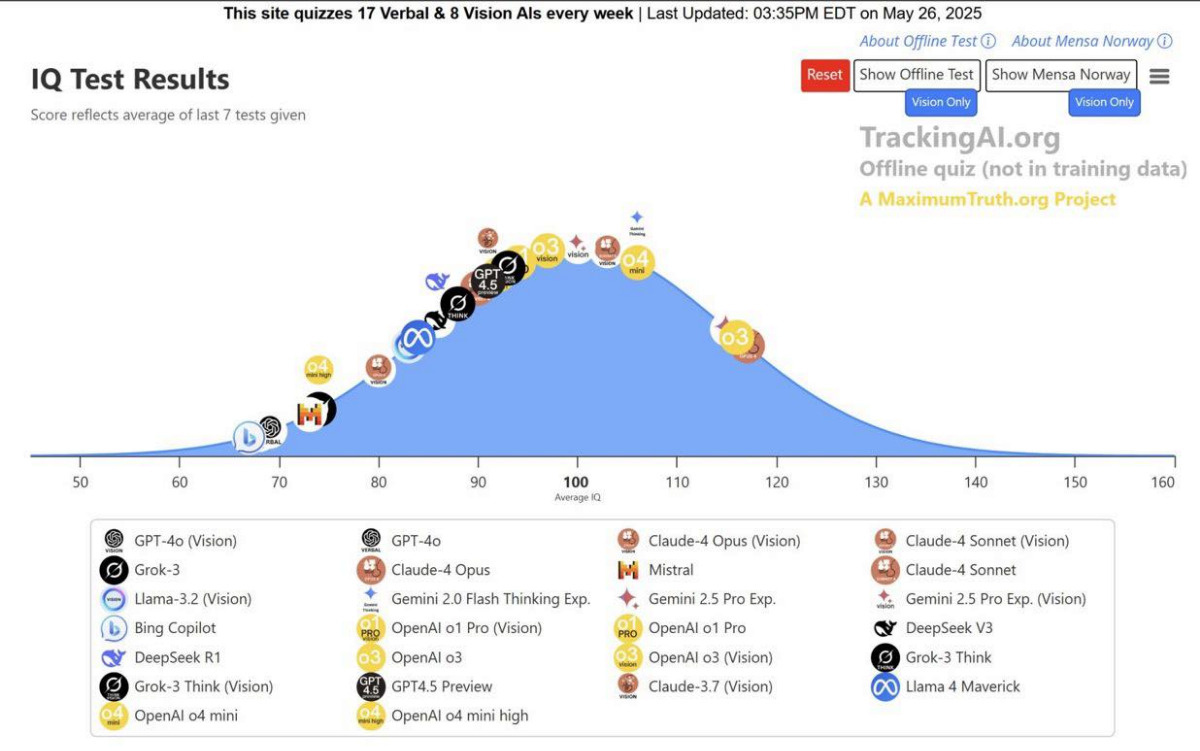

Ja to bym miał wynik na samym szczycie tej gorki
Teraz to już z górki.

Zaloguj się aby komentować
Hasti
Kosmonauta
Do czego wykorzystujecie AI? Czy ułatwia wam w jakiś sposób codzienne życie?
Mam wrażenie, że trochę zostaje w tyle w tym temacie a z drugiej strony ostatnio zadałem parę prostych pytań z fizyki chat gpt i nie byłem przekonany czy właściwie odpowiedział. Musialem to sprawdzić na piechotę i faktycznie się pomylił i po doprecyzowaniu pytania poprawił swój błąd.
Za to za każdym razem pisał durne teksty typu super pytanie! Świetne rozważania! Masz rację!
#chatgpt #openai #pytanie

@Hasti pracuję jako 'devops' - nie wszystkie technologie, które muszę ogarniać znam na 100%. Miałem ostatnio bitwę z MsSQLem, którą wygrałem dzięki GPT.
Generalnie bawię się dużo w domu w selfhosting i szeroko pojęty homelab - dzięki pomocy AI ogarnąłem wszystkie dockery i podobne (a nie mam tego w robo) w ekspresowym tempie.
Wątpię żeby LLMy zastąpiły programistów, ale na pewno trudno będzie tym początkującym się przebić

Do szukania informacji w internecie - przez perplexity - bo potrafi dobrze dobrać wyniki wyszukiwania do promptu, przebija się przez SEO, znajduje adekwatne linki i podaje źródła. Do tego chyba używam najwięcej.
Czasami do tworzenia/edycji kodu wprost, ale żebym miał większą pewność że będzie lepiej a nie gorzej to zazwyczaj po prostu opisuję bardziej dokładnie kolejne kroki co bym zrobił żeby mi wygenerował szybciej niż ja to naklikam, niż "zrób mi nowego facebooka/ubera od podstaw". No chyba że jest to jakiś jednorazowy skrypt który przestanie mnie interesować w momencie jak go wykonam, to wtedy nie muszę szczególnie wiedzieć co tam się dzieje, byle by działało.
Czasami do analizy tekstu, np. po transkrypcji podcastu sprawdzam czy w danym rozdziale będzie coś interesującego poruszane prosząc o streszczenie, albo czy Makłowicz coś gotuje w najnowszym odcinku czy tylko chodzi i gada ( ͡° ͜ʖ ͡°).
Czasami też do inspiracji, np. szukając prezentu dla kogoś, ale nie na zasadzie "podaj 10 najlepszych prezentów na dzień ojca", bo wyniki będą jak przy szukaniu w googlu "czy dziś jest niedziela handlowa". Pytam o podzielenie prezentów na różne kategorie, potem żeby dla każdej coś zaproponował. Potem żeby zróżnicował to dla różnych typów osobowości - w tabelkę. Potem ew. niech dla kontrastu poda typowe prezenty które można dać każdemu i na tej samej zasadzie ale nietypowe/szalone/bezsensowne/drogie itp. i ciągnę rozmowę.

Do odpisywania na debilne maile malezyjczykow. Serio. Generalnie u mnie w firmie duzo osob korzysta do oficjalnej korespondencji z roznej masci urzednikami xD
Zaloguj się aby komentować

NrmvY
★Osobistość

OpenAI prezentuje: O3 oraz O4-mini
OpenAI zaprezentowało modele o3 i o4-mini, które wprowadzają zaawansowane możliwości rozumowania, w tym analizę obrazów oraz samodzielne korzystanie z narzędzi ChatGPT, takich jak przeglądarka internetowa, interpreter Python, generowanie obrazów i analiza plików.Model o3 wyróżnia się najwyższą...
NrmvY
★Osobistość

GPT-4o - natywne generowanie obrazów oraz SORA bez limitów!
GPT-4o w końcu dostępny z natywną generacją obrazów! Efekty są na prawdę świetne. Do tego zniesione zostają limity korzystania z generatora wideo SORA. Teraz dostępny jest nawet w najtańszej subskrypcji, niestety z mniejszą rozdzielczością i krótszymi klipami (720p vs 1080p oraz 10s vs 20s dla...
NrmvY
★Osobistość

Pilnujcie dzieciaków żeby nie oglądały na YouTube tych filmów generowanych przez AI. Potem będą myślaly że słonie latają. To robi dzieciom wodę z mózgu. Dzieciaki uczą się jak funkcjonuje świat miedzy innymi z takich źrodeł. Będą problemy jeśli w młodym wieku będą uczyć się takich głupot. Najgorsze jest to że na pierwszy rzut oka wygląda to na nieszkodliwe filmiki ale w rzeczywistości młode umysły uczą się że tak wygląda rzeczywistość. #zalesie #rozkminy #oswiadczenie #youtube #openai #sztucznainteligencja

@DexterFromLab I co następne? Że może syreny nie istnieją?



@parabole Oczywiście, że istnieją


@parabole @UmytaPacha
Wy pokazujecie fragmenty bajek. Że niby od dawna są już tworzone takie filmy które nie pokazują rzeczywistości. Świetnie, ale bajka to bajka. Animacja jest odrożnialna od prawdziwego obrazu. Ale te badziewia które przewijają się na rolkach wyglądają jak prawdziwe filmy i w tym kontekście argumentacja z użyciem obrazków z kreskówek jest nie trafiona.

@DexterFromLab nie trzeba AI, wystarczy Psi patrol
e tam, od 2000 lat krąży taka jedna książka, i nic się nie stało. Co najwyżej trochę ludzi wierzy, że da się zmienić wodę w wino
Zaloguj się aby komentować
NrmvY
★Osobistość
![[ENG] xAI - prezentacja modelu Grok 3 oraz Grok 3 Mini](https://cdn.hejto.pl/uploads/posts/images/250x250/442291c53aaf89e4ef6cc7d367b41968.png)
[ENG] xAI - prezentacja modelu Grok 3 oraz Grok 3 Mini
xAI - firma należącą do #elonmusk zajmująca się sztuczną inteligencją zaprezentowała nowe modele AI Grok 3 oraz Grok 3 Mini.
Grok 3 nawiązuje równą walkę z topowymi aktualnie modelami wnioskującymi od #openai O3 Mini (high) oraz O1. Aktualnie zajmuje pierwsze miejsce w rankingu lmsys.
#ciekawostki...
Genialny wizjoner Musk najpierw wkupił się do OpenAI, potem odszedł, bo chciał by byli for-profit, a oni nie, potem jak OpenAI stworzyło ChatGPT i zaczęło na nim zarabiać to stwierdził, że to zła firma bo są for-profit, potem próbował stworzyć dla niej własną konkurencję, a teraz chce ich kupić za $100 mld? To są dopiero szachy 5D, my nie jesteśmy godni takiego geniusza.
#ai #elonmusk #openai

@lurker_z_internetu wiem, że macie prawo, ale kisnę z tych opinii internetowych fachur co "detale" znają z reddita i innych gówien. Plus tyrają u janusza

Ale wy naiwni jesteście, wydrukowane pieniądze to tylko liczby, cel zakupu x i zmiana propagandy z lewej na prawą podziałała

@lurker_z_internetu Ehh, a mógłby się słuchać jakiegoś randoma z Hejto, wtedy to już dawno by wylądował na Marsie
Zaloguj się aby komentować

W związku z ostatnimi oskarżeniami #openai wobec #deepseek o to że ich okradają przypomniała mi się riposta Gatesa gdy Jobs oskarżył go o kradzież pomysłu na interfejs graficzny:
Steve Jobs oskarżył Billa Gatesa o kradzież interfejsu graficznego, gdy Microsoft wprowadził system Windows, który miał podobieństwa do interfejsu Apple'a. W odpowiedzi na te zarzuty, Gates podobno odpowiedział: „No, Steve, myślę, że możemy spojrzeć na to w ten sposób: obaj mieliśmy bogatego sąsiada o nazwie Xerox, a ja włamałem się do jego domu, aby ukraść telewizor, i odkryłem, że ty już go ukradłeś.”
To stwierdzenie odnosiło się do faktu, że zarówno Apple, jak i Microsoft czerpały inspirację z interfejsu graficznego opracowanego wcześniej przez Xerox PARC (Palo Alto Research Center). Jobs odwiedził Xerox PARC w 1979 roku i zobaczył tam wczesne wersje interfejsu graficznego, które później wpłynęły na rozwój systemu operacyjnego Apple'a. Gates argumentował, że obie firmy korzystały z podobnych pomysłów, które nie były wyłącznie oryginalne dla Apple'a.
Opis wygenerowany z deepseek bo nie chciało mi się robić zdjęcia z książki xD
Zaloguj się aby komentować
NrmvY
★Osobistość
![Nawet 500 miliardów dolarów zostanie zainwestowane przez rząd USA w rozwój technologii AI w USA. [ENG]](https://cdn.hejto.pl/uploads/posts/images/250x250/145460500851d8071501a4ead2bc284a.jpg)
NrmvY
★Osobistość

OpenAI o3 and o3-mini—12 Days of OpenAI: Day 12 - Pokonanie benchmarku ARC-AGI - krok milowy.
OpenAI model o3 przebija barierę 85% (poziom ludzi) w bardzo trudnym benchmarku ARC-AGI.
Benchmark jest bardzo prosty dla ludzi (przykład na obrazie) albo bardzo trudny dla AI. 85% to granica jaką osiąga przeciętny człowiek. Benchmark nie opiera się na wiedzy encyklopedycznej, ale sprawdza...


Oskarżył ChatGPT o kradzież na masową skalę. Właśnie znaleziono go martwego w mieszkaniu
Suchir Balaji, 26-letni były pracownik OpenAI, zdobył niedawno sławę jako sygnalista. Twierdzi, że jego były pracodawca stworzył technologię GPT przy pogwałceniu licznych praw, w tym autorskich. Niestety nie będzie zeznawać w sądzie.
O Suchirze Balaji było głośno w branżowych mediach już w...


Czyli że co jak whistleblowerzy popełniają "samobójstwa" to jest kwestia biologiczna, naturalna śmierć jak śmierć, ale jak ktoś zabija CEO to jest tragedia, dramatyczne doświadczenie, metafizyka, spotkanie z najwyższym.

Pytałem AI czy to prawda i pisze że nieprawda.


@Half_NEET_Half_Amazing Popełnił samobójstwo strzelając sobie w plecy. Siedem razy.
Zaloguj się aby komentować

Kiedy AI spotyka się z poezją. "Dreams" z nowego albumu poetyckiego IN-Q, The Never Ending Now w eksperymencie reżysera Wayne’a Price’a. Wideo pokazuje możliwości Sora, narzędziu do tworzenia wideo od OpenAI. Efekt? Unikalna mieszanka realizmu z nutą retro stylu dokumentalnego.
https://www.youtube.com/watch?v=qnXfZ_cQgEU
#ai #sora #openai

@bartas - Panie trzeci adminie - Pana wpis to doskonały przykład, że filmiki z YouTube się źle osadzają i nie są się ich wyświetlić na hejto

Nic ciekawego.

Sora- najpotezniejsze narzedzie do ktotego nikt nie ma dostępu. Nikt procz kilku wybrancow.
Zaloguj się aby komentować