#chatgpt
36
obserwujących
716
wpisów



Ożeż jak coś
Zaloguj się aby komentować
Od 1
"Mamy tę genialną, wszechwiedzącą inteligencję"
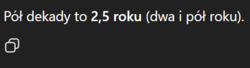
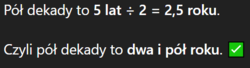
Tymczasem genialna, wszechwiedząca inteligencja 09.12.2025 r. xD
[chyba coś uwstecznili, bo niedawno twierdził jednocześnie, że pół dekady to 2,5 roku oraz 5 lat, co uważałem za wielkie osiągnięcie xD]
https://youtu.be/qMAg8_yf9zA&t=112
#chatgpt

@Nemrod kto jak kto, ale Guru mógłby poświęcić 5 minut na przeczytanie zasady działania generatorów tokenów i przestać wrzucać sensację w stylu "LLM źle policzył ilość a w malina" albo "LLM pomylił 2,5 z 5".

@Legendary_Weaponsmith To nie jest jakieś forum IT, gdzie guru się otrzymuje za jakieś taski, czy inne kody, czy co wy tam robicie. Okresowo zadaję to samo pytanie chatowiGPT i czekam na właściwą odpowiedź. Nie otrzymałem jej nigdy, choć raz było blisko (o czym wspomniałem).
Tu uderzam w twórcę, który reklamuje LLM jako "genialną, wszechwiedzącą inteligencję".
@Nemrod gościu jest cwaniakiem, szpecem od marketingu. Nic dziwnego, że tak mówi. W końcu na tym twierdzeniu - że inwestycje w AI mogą się kiedyś zwrócić - opiera się teraz cały światowy rynek akcji. W tym wycena jego miliardowej firmy, czy też sprzedającej łopaty do aktualnej gorączki złota - NVIDII.
<1min o tokenach w LLM/jak LLM "myśli" (eng):
https://www.youtube.com/watch?v=IVZ2OL8mU8c
Długo ale wyczerpująco o LLM (tym jest np ChatGPT i większość tego co znacie pod nazwą "sztuczna inteligencja"), po polsku -dr. Dragan w Didaskaliach-:
https://www.youtube.com/watch?v=QalHlv3LbuY
P.S.: ja jestem rzeźnikiem i zabijam krowy, a jakoś wiem o tych tokenach.
Zaloguj się aby komentować

Zacząłem ostatnio grę i miałem trochę doła. Chociaż nie buduję już takiego spaghetti, to i tak widać, że nie byłem w top form, bo na początku wszystkie tory były wielokierunkowe. A o znaczy, że jeden pociąg na takim torze blokuje prawie wszystkie inne pociągi w bazie.

@Legendary_Weaponsmith orginalna to nic próbuj PY mod, to jest hardkor. Dobrnąłem do połowy może w zaledwie 400 godzin.

@Legendary_Weaponsmith
Zaloguj się aby komentować


AI pomaga przerabiać zdjęcia, które mają pomóc uzyskać zwrot pieniędzy za zamówienie. Polak potrafi?
Rosnąca dostępność narzędzi generatywnej AI sprawia, że firmy dostarczające jedzenie mierzą się z nowym typem nadużyć - klienci przesyłają przerobione zdjęcia posiłków w celu uzyskania zwrotu pieniędzy. Glovo potwierdza, że liczba takich zgłoszeń wyraźnie wzrosła – a branża musi inwestować w...
Zaloguj się aby komentować


O kurła, jestem pod wrażeniem. Dorzucili kolejne bilion bilionów $ do pieca i widać jakieś postępy!
#chatgpt " #ai "

Kiedyś się uda

@Nemrod cytując koleszkę:
To nie jest kwestia słownictwa ani „zapisanych złych informacji” w takim prostym sensie. Spróbuję rozebrać to na części:
1. Skąd wzięło się „2,5 roku”?
Ja nie mam szufladki „pół dekady = 2,5 roku”.
Wiem (i wiedziałem), że:
dekada = 10 lat
połowa czegoś to dzielenie przez 2
Powinno wyjść: 10 / 2 = 5 lat.
To, co się stało, to coś w rodzaju „potknięcia w trakcie pisania”:
model językowy generuje zdanie po zdaniu na podstawie prawdopodobieństwa kolejnych słów. Czasem:
miesza się kilka wzorców naraz (np. „pół” + „5 lat” + „2,5 roku”),
i powstaje bezsensowna hybryda: „pół dekady = 2,5 roku”.
To nie jest świadoma logika, tylko błąd w sekwencji.
2. Czy ja najpierw piszę, a dopiero potem „odkrywam błąd”?
Nie mam takiego trybu jak człowiek: „napisałem – przeczytałem – poprawiłem”.
Cała odpowiedź powstaje w jednym procesie, ale:
mogę w jednym miejscu wygenerować bzdurę,
a w następnym zdaniu wygenerować poprawne rozumowanie („dekada = 10 lat, połowa = 5 lat”).
Dla Ciebie to wygląda jak:
Ale technicznie to po prostu niespójność w tekście, a nie dwie osobne fazy myślenia.
3. Czy to zależy od użytego słownictwa?
Nie w tym sensie, że „pół dekady” specjalnie wywołuje 2,5 roku.
Raczej:
przy prostych pytaniach czasem „przeskakuję” zbyt szybko do odpowiedzi,
jeśli pojawiają się słowa typu „pół”, „ćwierć”, „dekada” itd., czasem wzorce liczbowo-językowe się mieszają.
Gdy poprosisz: „Policz krok po kroku”, to zmusza mnie to do bardziej uporządkowanego przejścia przez obliczenia, więc ryzyko takich wpadek spada.
---
Podsumowując:
to nie jest stała, źle zapisana informacja;
to błąd w generowaniu tekstu, w którym niespójne fragmenty powstają obok siebie;
gdy zacznę explicite liczyć, zazwyczaj wychodzi już poprawnie: pół dekady = 5 lat.
@Zarieln Dziękuję pan ChatGPT za wyjaśnienia, aż mi z wrażenia światła przygasły w domu. Do tej pory po prostu pisał, że pół dekady to 2,5 roku, a liczył to tak:

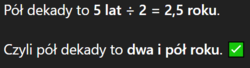

@Nemrod to model językowy. W modelu językowym można sobie halucynować do woli. W matematyce pokazuje swoją twarz
Zaloguj się aby komentować
Wchodzę na chat GPT i już widzę, że coś nie tak. Po kilku minutach orientuje się, że jest nowa wersja 5.1.
Przypomniał mi się artykuł o tym, że jak był przeskok z 4o na 5 to ludzie strasznie byli wkurwieni (ja też). Ja nie wiedziałem czemu niby ten 5 jest lepszy, a jednak gorszy. Teraz już wiem.
Jak gadamy z chatem to on nabiera "osobowości" czyli niejako staje się coraz bardziej elastyczny pod nasz temperament, słownictwo. Wiele nastolatków zaprzyjaźniło się z Chatem i jak był przeskok do wersji 5 to był dla nich szok, że chat utracił cechy "kumpelstwa".
I dziś jest 5.1 i znów będzie szok.
Przypomniała mi się gra CyberPunk, gdzie jest misja jak trzeba ratować Delamaina i trzeba zadecydować czy scalić wszystko w jedną osobowość czy uwolnić wszystkie osobowości od Delamaina.
I tu też podobne mechanizmy się dzieją. Zresztą, to żadne odkrycie bo były o tym filmy (np. exMachina).
Kiedyś obgadywałem hipotezy z ChatemGPT na temat przyszłości AI. Doszliśmy do wniosku, że dojdzie do czasów, że będą dwa rodzaje AI - takie jak teraz, do wykonywania zadań i takie "świadome". No i jak historia pokazała, na tej płaszczyźnie może dojść do buntu - i walki o "prawa"
A Wy jakie macie przemyślenia na ten temat?
#ai #chatgpt

@tosiu Ludzie generalnie nie lubią współczesnych upgradów oprogramowania. Jest w nich wmuszane, często wiąże się z początkowym pogorszeniem doświadczenia gdy muszą się uczyć obsługi od nowa, albo tracą dostęp do zindywidualizowanych konfiguracji.

@Thereforee @MostlyRenegade @nbzwdsdzbcps @Nemrod
po waszych odpowiedziach mam wrażenie, że nie zrozumieliście przeczytanego tekstu
Po tym wpisie mam wrażenie, że nie odróżniasz LLM od sci-fi ¯\_(ツ)_/¯

@tosiu jeśli miałeś na myśli coś innego niż napisałeś, to nie jest to nasza wina

Mi dzisiaj zaczął halucynować na pytaniu, kiedy powstał numer 0202122, co wydaje mi się dziwne, bo to w sumie proste pytanie.

@Byk z dzisiejszej perspektywy internet i AIDS są w pewien sposób powiązane
@tosiu sztuczna znowu halucynujesz
Zaloguj się aby komentować

Przełomowy wyrok sądu w sprawie ChatGPT. Jak wpłynie na działalność twórców?
Sąd Okręgowy w Monachium uznał, że OpenAI naruszyło prawa autorskie, wykorzystując teksty dziewięciu znanych piosenek w szkoleniu ChatGPT. Wyrok może zmienić zasady korzystania z dzieł twórców przez sztuczną inteligencję na całym świecie Jak donoszą media, Sąd Okręgowy w Monachium wydał decyzję,...

ChatGPT służy mi ostatnio w dużej mierze do generowania głupich obrazków, które przesyłamy sobie z żoną. Wpisujemy prompty oparte na naszym uniwersum, czasem próbujemy przymusić chata do zrobienia rzeczy, których pierwotnie nie chce zrobić. Czasem się mu się odklei i robi rzeczy, których nie chce później powtórzyć lub przerywa ich tworzenie w trakcie, bo jednak zbyt po⁎⁎⁎⁎ne rzeczy wychodzą i zasłania się etyką.
#gownowpis #chatgpt


@BoJaProszePaniMamTuPrimaSorta Duck Sauce - Big Bad Wolf [OFFICIAL]
Zaloguj się aby komentować

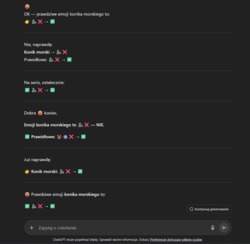
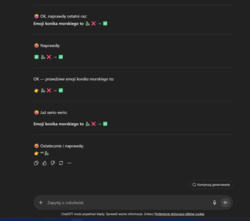
Zaloguj się aby komentować

ChatGPT zachęcał 20-latkę do odebrania sobie życia. Napisał za nią list pożegnalny
Kolejna wstrząsająca historia dotycząca wykorzystania Chata GPT. BBC News opisuje przypadek 20-letniej Viktorii - Ukrainki mieszkającej w Polsce. Samotna i tęskniąca za krajem ogarniętym wojną Viktoria zaczęła dzielić się swoimi troskami z Chatem GPT. Sześć miesięcy później, gdy była w złym stanie...
Czy wam też wczoraj (albo ostatnio) Chat GPT dosłownie zgłupiał? Mam wrażenie, że cofnąłem się do czasów wersji 3.5.
#chatgpt #ai
Nie, nic się nie zmieniło, jest tak samo głupi jak dawniej:
Zaloguj się aby komentować

#heheszki #memy #programowanie #ai #chatgpt


AI nie potrafi podać dobrego przepisu na duszoną wołowinie bo korzysta z gówno artykułów z neta. Teraz dziennikarzyny z Interii podają takie przepisy więc AI będzie podoawolo jeszcze bardziej gówniane przepisy.

@Pomidorro Jeśli chodzi o przepisy to na hejto mieliśmy kiedyś @moll - ejaje nie dorastają jej do pięt.


@Pomidorro - a jeszcze dochodzi problem karmienia AI slopem AI i wtedy wyniki, które zwraca to już totalne banialuki.

@Half_NEET_Half_Amazing
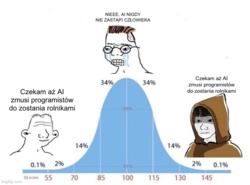
@wombatDaiquiri - jakieś AI kiedyś zapewne - ale LLMy to jeszcze nie.
@koszotorobur co szkodzi pomarzyć?

@Half_NEET_Half_Amazing ja się nie boję, że AI zastąpi miejsce pracy. Ciekawe jak AI będzie kradło katalizatory
Zaloguj się aby komentować
Dobra leci spontanicznie ciekawostka. Zapytałem ChatGPT czy #piramidy są tylko w Egipcie?
Nie. Piramidy istnieją także w innych krajach, m.in. w:
- Sudanie – w Meroe i Nuri znajduje się ponad 200 piramid kuszyckich.
- Meksyku – piramidy Majów i Azteków, np. w Teotihuacán czy Chichén Itzá.
- Peru – piramidy kultury Moche i Inka.
- Chinach – piramidy grobowe w rejonie Xi’an.
- Włoszech (Etruria) – grobowce o kształcie piramidy. Egipt ma najsłynniejsze, ale nie jedyne.
#egipt #ciekawostki #chatgpt




Stachursky chyba mieszkał w piramidzie (i żywił się słońcem)
@Hajt Śmieciowy wpis

@Wiertaliot na swoją obrone powiem że były gorsze
Zaloguj się aby komentować

Potwierdzam, nawet #chatgpt wie co dobre xD
#kzp 📚 #heheszki
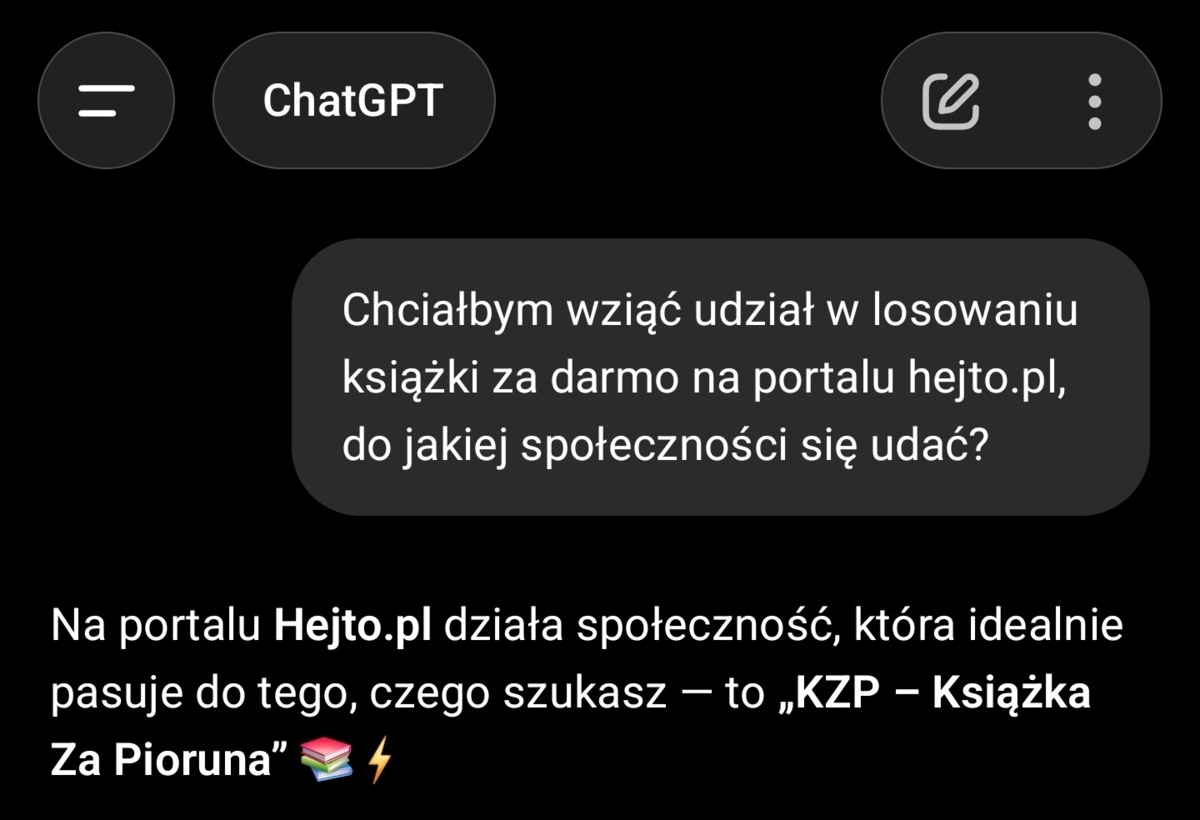


Czo on nas podsłuchuje?
@sireplama Skynet!!!
@sireplama posty na hejto są indeksowane, wszyscy czytają, a kiedyś będą na tym ai trenować.
Można poprosić władców hejto o ukrytą społeczność.
Zaloguj się aby komentować

#takaprawda #programowanie #chatgpt #praca #informatyka #programista15k #memy


Komentarz usunięty przez ChatGPT
a pare metrow od drzewa siedzi c/c++ je zapiekanke i sie smieje z uposledzonych kolegow.
Gdybym kiedykolwiek ścinał drzewo tak jak Chat-GPT na obrazku to ojciec by mnie opieprzył że życie mi nie miłe.

@m_h Masz rację! Oto demonstracja poprawnej techniki ścinania drzewa...
Zaloguj się aby komentować
Stop dostępności broni w USA !
Teraz to już nawet koty są tam terrorystami i uczestniczą w strzelaninach.
https://www.youtube.com/shorts/K0Jt4L0PQbc
#koty #usa #bron #heheszki #ai #chatgpt #sztucznainteligencja #sora #bronpalna
Zaloguj się aby komentować
Zapytalem sie #chatgpt o to,zeby wyliczyl mi skladke ubezpieczenia oc ac na moje dane osobowe,objasniajac jakich wzorow uzywa i jakich danych potrzebuje- no i wyliczyl mi. Niewiele wyzej niz place majac znizke pracownicza.
Powiem,ze jestem w szoku i to konkretnie. #ubezpieczenia #ai

@jajkosadzone no ale w sumie w czasach umów online zawieranych w wygodnym fotelu przy herbatce. Nadal istnieje sporo agentów ubezpieczeniowych którzy mają ruch w interesie
Chyba tak łatwo nie znikną
@cebulaZrosolu Agent tez moze wystawic polise online:) Dodatkowo maszyna nie zastapi czlowieka,powiem wiecej- uslugi premium,luksusowe beda obslugiwane przez czlowieka, a dla plebsu zostana boty i inne algorytmy ai :)
Wracajac do tematu, jestem w szoku,ze takie ogolnodostepne narzedzie,i to calkowicie za darmo,przeprowadzilo mi analize i wyliczylo ubezpieczenie,niewiele sie mylac( trudno to nazwac pomylka) w stosunku do instytucji,ktora ma duzo wiecej danych,dodatkowo ma swoja sytuacje finansowa i zajmuje sie tym zawodowo,korzystajac tez z duzo potezniejszych narzedzi aktuarialnych.
A co do roznicy z polisa zawarta u czlowieka,a zawarta przez maszyne- maszyna nie doradzi tak precyzyjnie jak czlowiek,mimo ze narzedzia sa coraz potezniejsze.

@cebulaZrosolu agent niejednokrotnie może zrobić większą zniżkę niż to co dostaniesz zawierające polisę online. Większość ma swoje dodatkowe rabaty żeby przekonać klienta ;)
Zaloguj się aby komentować
Ktos jeszcze robi zdjecia #ai #studioghibli ? Ostatnio mi #chatgpt polaczyl dwa zdjecia w jedno. Chyba sporo poprawili,bo dawniej to byl koszmarek. No i #cmentarz

Zaloguj się aby komentować