redve
Gruba ryba
Pytanie do ogarniających ludzi #machinelearning #uczeniemaszynowe #sztucznainteligencja #datascience
Dopiero wczoraj ogarnąłem podstawy PyTorch na tyle, żeby zrobić prosty model do klasyfikacji danych ze zbioru MNIST.
Ogólnie coś tam matematyki i ML ogarniam (wcześniej używałem tensorflow), więc to nie jest też tak że wczoraj sie nauczyłem co to jest ML.
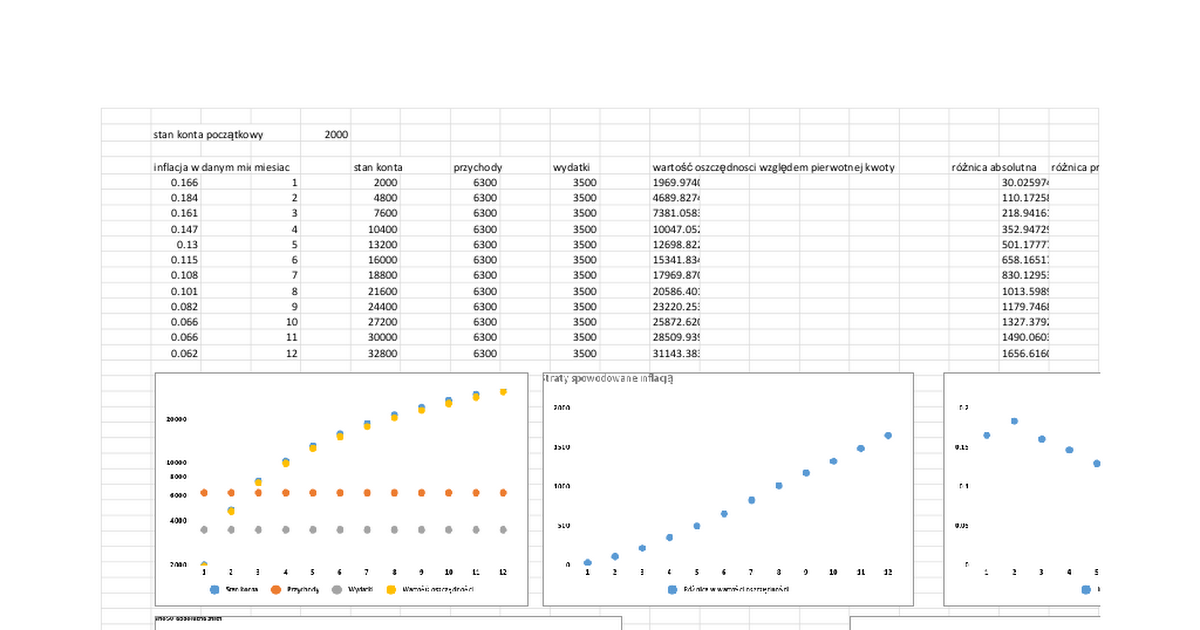
Trafiłem na pracę Microsoftu o modelu do czytaniu struktury tabel ze zdjęć https://arxiv.org/pdf/2208.04921
Problem w tym że model nie został nigdzie opublikowany, ogólnie niewiele znalazłem na ten temat poza pracami naukowymi od tych samych ludzi.
Wg waszej oceny, jak bardzo możliwe odtworzenie tego modelu, i uzyskanie chociaż zbliżonej skuteczności?
Znalazłem nowszą, bardziej rozbudowaną wersje tej samej pracy https://arxiv.org/pdf/2303.11615 w które jest jakby więcej szczegółów. Niestety moja wiedza jest zbyt skromna żeby po przeczytaniu ocenić na podstawie tej pracy czy uda mi sie to powtórzyć
Dopiero wczoraj ogarnąłem podstawy PyTorch na tyle, żeby zrobić prosty model do klasyfikacji danych ze zbioru MNIST.
Ogólnie coś tam matematyki i ML ogarniam (wcześniej używałem tensorflow), więc to nie jest też tak że wczoraj sie nauczyłem co to jest ML.
Trafiłem na pracę Microsoftu o modelu do czytaniu struktury tabel ze zdjęć https://arxiv.org/pdf/2208.04921
Problem w tym że model nie został nigdzie opublikowany, ogólnie niewiele znalazłem na ten temat poza pracami naukowymi od tych samych ludzi.
Wg waszej oceny, jak bardzo możliwe odtworzenie tego modelu, i uzyskanie chociaż zbliżonej skuteczności?
Znalazłem nowszą, bardziej rozbudowaną wersje tej samej pracy https://arxiv.org/pdf/2303.11615 w które jest jakby więcej szczegółów. Niestety moja wiedza jest zbyt skromna żeby po przeczytaniu ocenić na podstawie tej pracy czy uda mi sie to powtórzyć