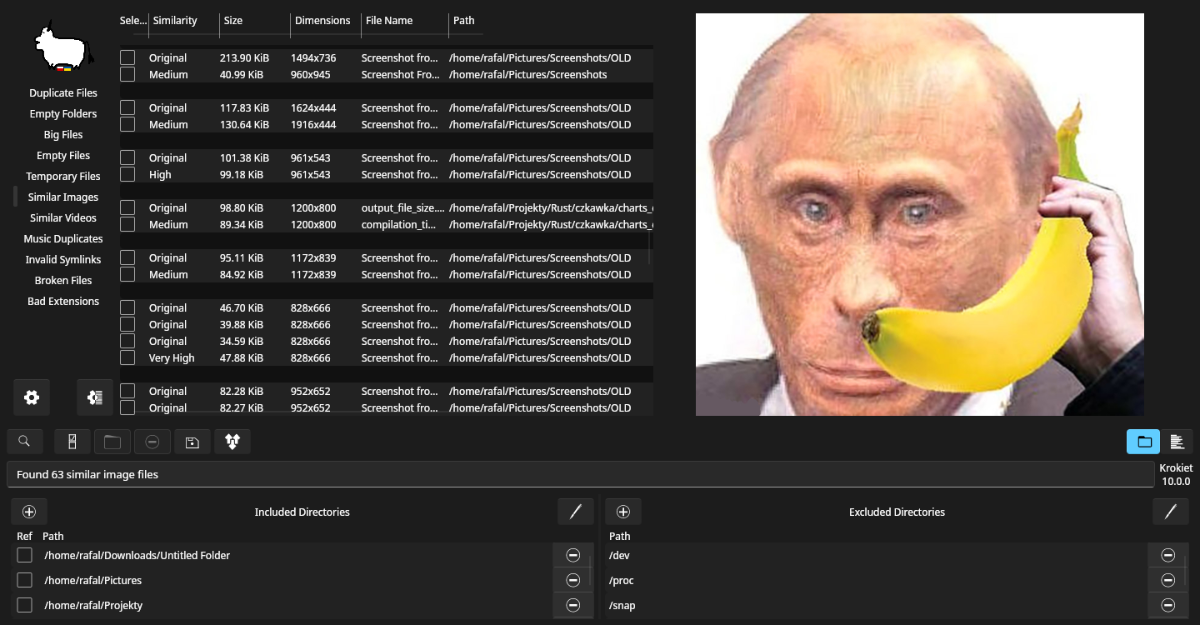
Osiem miesięcy po wydaniu Czkawki/Krokieta 7.0, nadszedł czas na wydanie wersji 8.0.
Dla ludzi niekojarzących programu, to jest to aplikacja do czyszczenia plików z duplikatów i jest dostępna na windowsa, linuxa, macos.
Lista Zmian(po angielsku, bo tłumaczenie niezbyt wiele ma sensu)
### Breaking changes
- Due to the removal image_type from image struct, old cache files are incompatible with new version and should be regenerated from scratch(it uses new name)
- Some CLI arguments could change short name, due fixing ambiguous names
### Known regressions
- Slint 1.8 which Krokiet uses requires femtovg 0.9.2 which broke font rendering - https://github.com/slint-ui/slint/issues/6298
### CI
- Providing nightly builds
- Added finding duplicated options in CLI
### Core
- Removed some unnecessary panics
- Simplified usage of structures when sending/receiving progress information
- Added Median hash algorithm
- Fixed compilation with Rust >=1.80
- Extracted tool input parameters, that helped to find not used parameters
- Added new mod to find similar music only in groups with similar title tag
- Printing to file/console no longer uses two backslashes in windows paths
- Fixed panic when failed to decode raw picture
- Remove useless saving/loading cache when there is no files to check
- Filtering hard links on windows
- Added jxl support
- Added avif support(via external C library, not enabled by default)
- Integer overflow are enabled by default(prepare for reporting bugs, slower performance and general unstability)
- Fixed crash when loading invalid image cache
### Krokiet
- Fixed invalid default hash size in similar images
- Fixed and added more input parameters to the application
- Fixed problem with loading invalid preset
- Fixed crash when using 8 hash size with small similarity
- Disabling buttons when no files were found
- Changed way to close/open panel at bottom
- Modify logo a little
- Avoid errors when trying to load preview of not supported file
- Added ability to show preview of referenced folders
- Enable selecting with space and jumping over entries with arrows and opening with enter
- Added button to rename files with invalid extension
### GTK GUI
- Fixed and added more input parameters to the application
- Added option to use external libraries instead gtk pixbuf loader for previews
- Using static runtime with zstd compression in appimage
- Restoring flatpak builds
- [External] Mac homebrew version of app - https://formulae.brew.sh/formula/czkawka
### CLI
- Added options to find/remove images by size
- Fixed and added more input parameters to the application
- Fixed crash when stopping scan multiple times
- Print results also in debug build
- Added support for selecting reference directories
Przyszłość
Przez blisko pół roku nie stworzyłem ani jednego commita, bo musiałem nieco odpocząć od projektu, bo nieco się wypaliłem.
W pracy zaczynam coraz więcej programować w rust, więc widzę że sam projekt nie jest najwyższej jakości i architektura aplikacji wymaga masy zmian(na które niekiedy za późno, bo wymaga to przepisania całej aplikacji) choć częściowo staram się refaktorować to co możliwe.
Jednak jednocześnie mam coraz mniej chęci, zajmować się poza pracą tym, co robię w czasie pracy, czyli głównie programowaniem - rozpoczynając projekt pracowałem w nieco innej branży, więc rozwijanie aplikacji było fajną odskocznią od zwyczajnych zadań.
Istnieje wiele głosów o konieczności przeprojektowania UI by było ono przystępniejsze jak i zaimplementowania nowych ważnych funkcji tj. pauza/wznawianie czy rozszerzenia opcji wyszukiwania duplikatów.
W teorii brzmią one sensownie, jednak są one problematyczne z pewnych powodów:
- główny ciężar implementacji zmian spada na mnie. Każdą funkcję trzeba najpierw przemyśleć, zaimplementować, przetestować, powalczyć z błędami związanymi z zewnętrznymi bibliotekami a następnie wspierać i modyfikować gdy to konieczne. Już teraz jestem autorem niemal 90% zmian i nie wygląda by cokolwiek się zmieniło lub by ktoś inny przejął na siebie w znaczącym stopniu ten ciężar.
- jestem słaby z tworzenia interfejsów - mimo chęci, zaproponowane mi różne koncepcje nowego wyglądu aplikacji nie wydawały mi się zbyt wydajne. Interfejs powinno się stosunkowo łatwo używać i powinien być płynny nawet przy dziesiątkach tysiącach wyników. Myślę, że częściowo mi się to udało zrobić, ale jeśli uważacie że można zrobić to lepiej, to polecam użyć core, tak jak to robi cli, czkawka i krokiet i stworzyć swoją własną wariację gui
- aplikacja obecnie jest wypełniona trybami(11 jeśli się nie mylę) a każdy tryb ma nawet po kilka opcji do konfiguracji. Dość łatwo dodając zbyt dużo opcji jest w stanie się stworzyć nieczytelne gui i kod, który później będzie problematyczny w obsłudze(z takimi problemami głównie mierzyłem się na początku istnienia projektu, gdzie wesoło dodawałem nowe tryby) - nie mówię że to koniec i że nic nowego nie będzie dodawane, tylko że trzeba to robić z rozwagą.
Mimo tych wszystkich problemów, jak wskazuje wydanie nowej wersji, ciągle jeszcze mam siły na pokonywanie przeciwności i zapewne aplikacja będzie się rozwijała swoim spokojnym tempem.
Cena — za darmo to i ocet słodki - licencja MIT/GPL
Repozytorium z kodem - https://github.com/qarmin/czkawka
Pliki do pobrania — https://github.com/qarmin/czkawka/releases
#programowanie
#tworczoscwlasna